Downloads: Jupyter Notebook:
This is the 1.5th post of a 3 part post to explore google’s Sentence Piece’s(SP) tokenizing power.
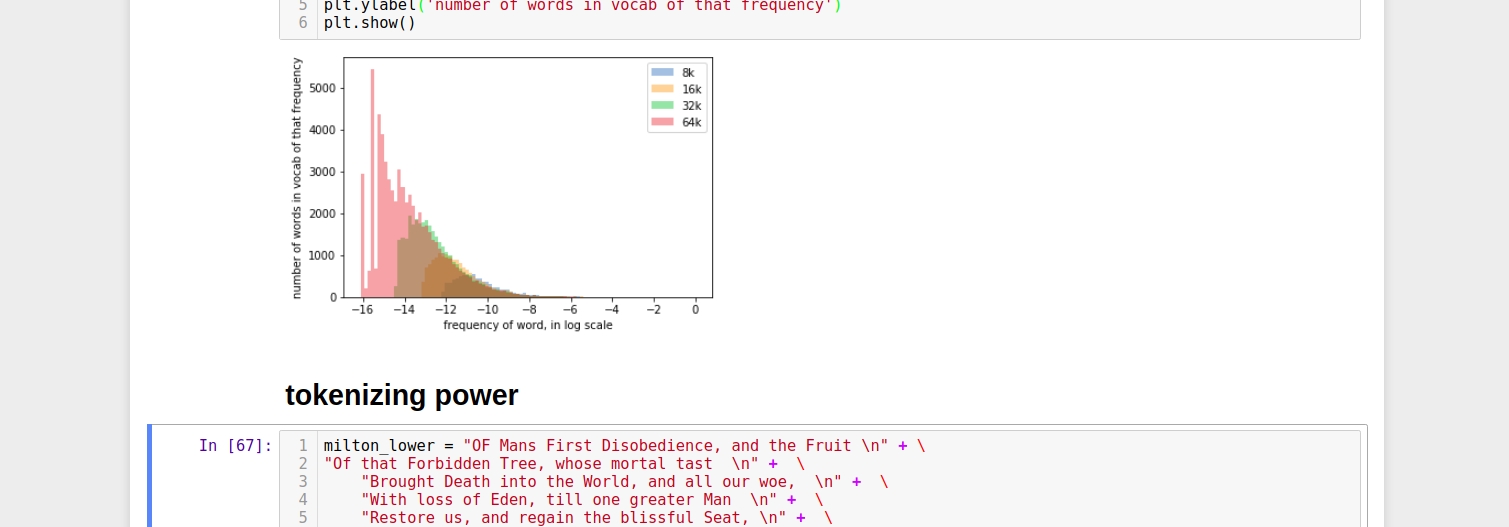
This one is optional. I’m just looking at distribution of words and their frequencies.
At the end, I have also incl...
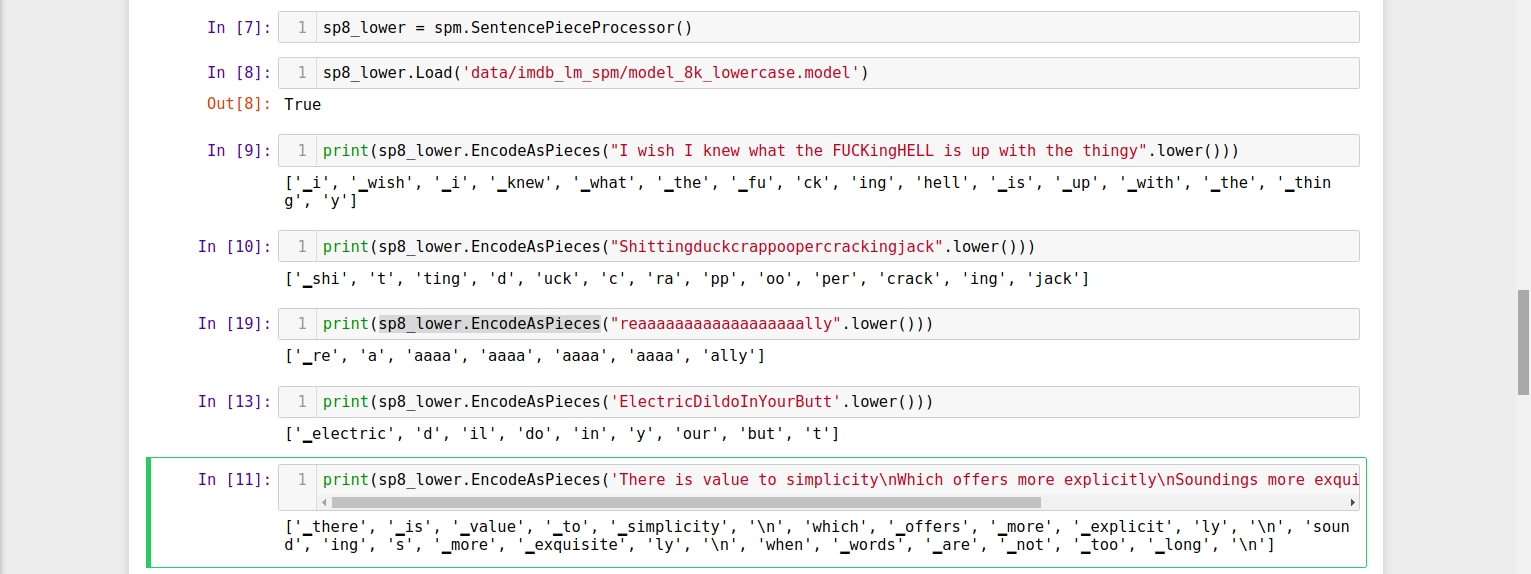
Conclusion: Sentence Piece is much better at tokenizing, retaining all information even when word is not in vocab.
Downloads: Jupyter Notebook:
This is the first post of a 3 part post to explore google’s Sentence Piece’s(SP) tokenizing power.
...
Conclusion: You can have lots of fun with plain image data sets, without any labeling at all!
Downloads:
PASCAL dataset:
PASCAl is a fun annotated dataset. It contains image data, with object identification and location.
For example,
Then I t...
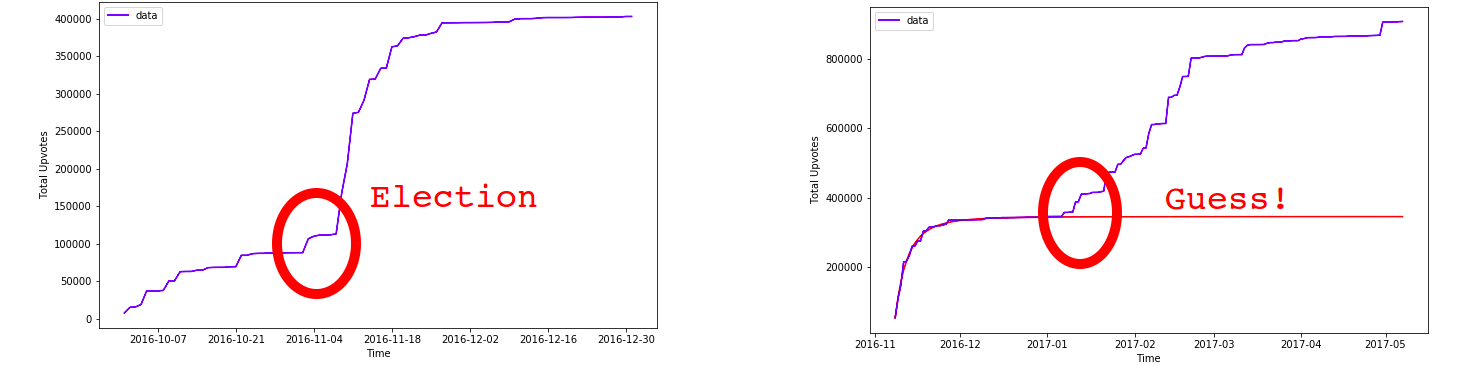
Conclusion: Trump Jokes are very much like cancer: they grow, then they stablize in a predictable manner. Like Cancer.
Downloads: Jupyter Notebook:
Data/CSV:
Cancer Model:
In the last post, we looked at which politician is made fun of when.
In ...
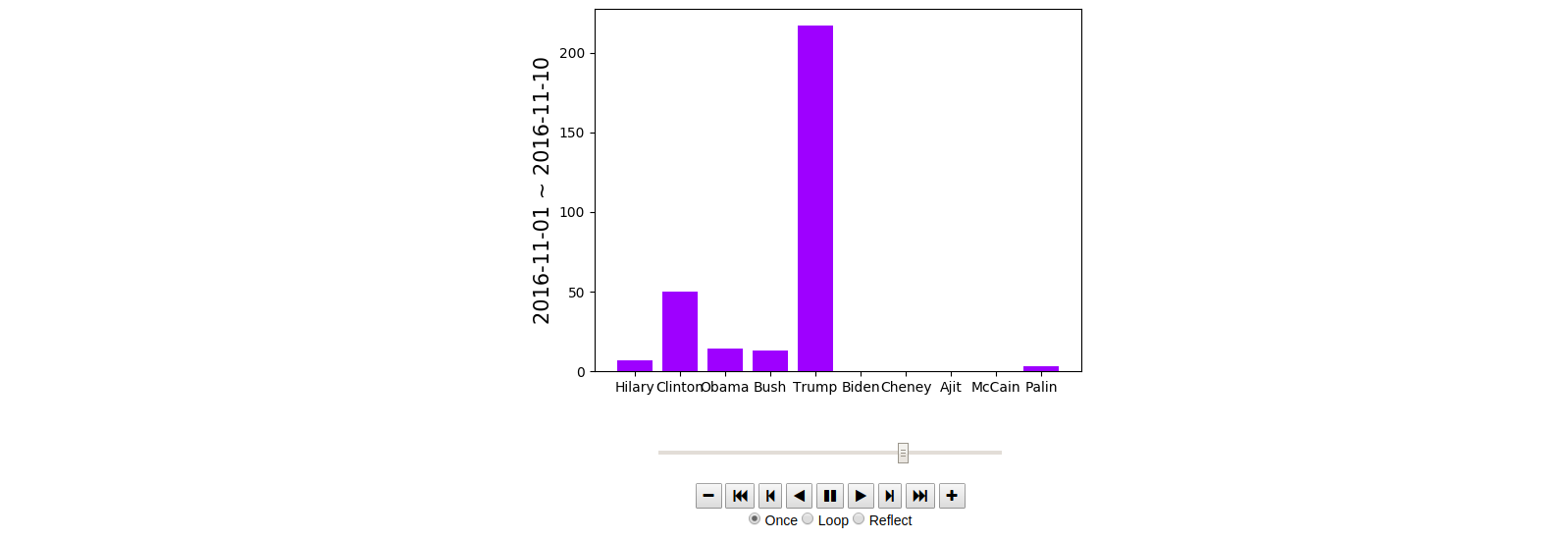
In the last post, we did some comparison between jokes.
This is a friendly light excursion to simple animation, a nice way to visualize our result.
TFIDF is used to figure out what are the intersting topics of the joke corpus. The answer is prett...